Deep reinforcement learning for the control of airfoil flow separation
-
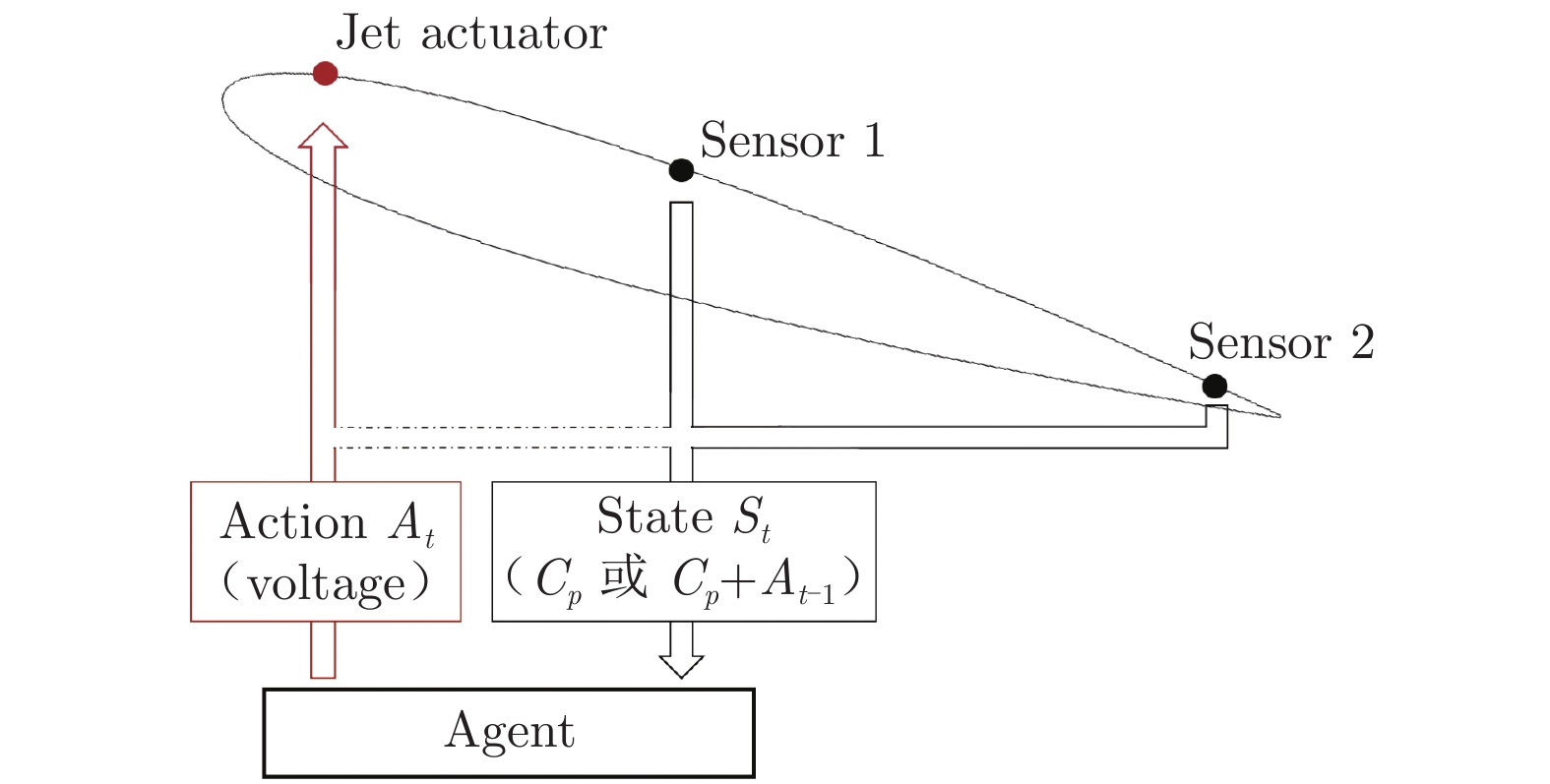
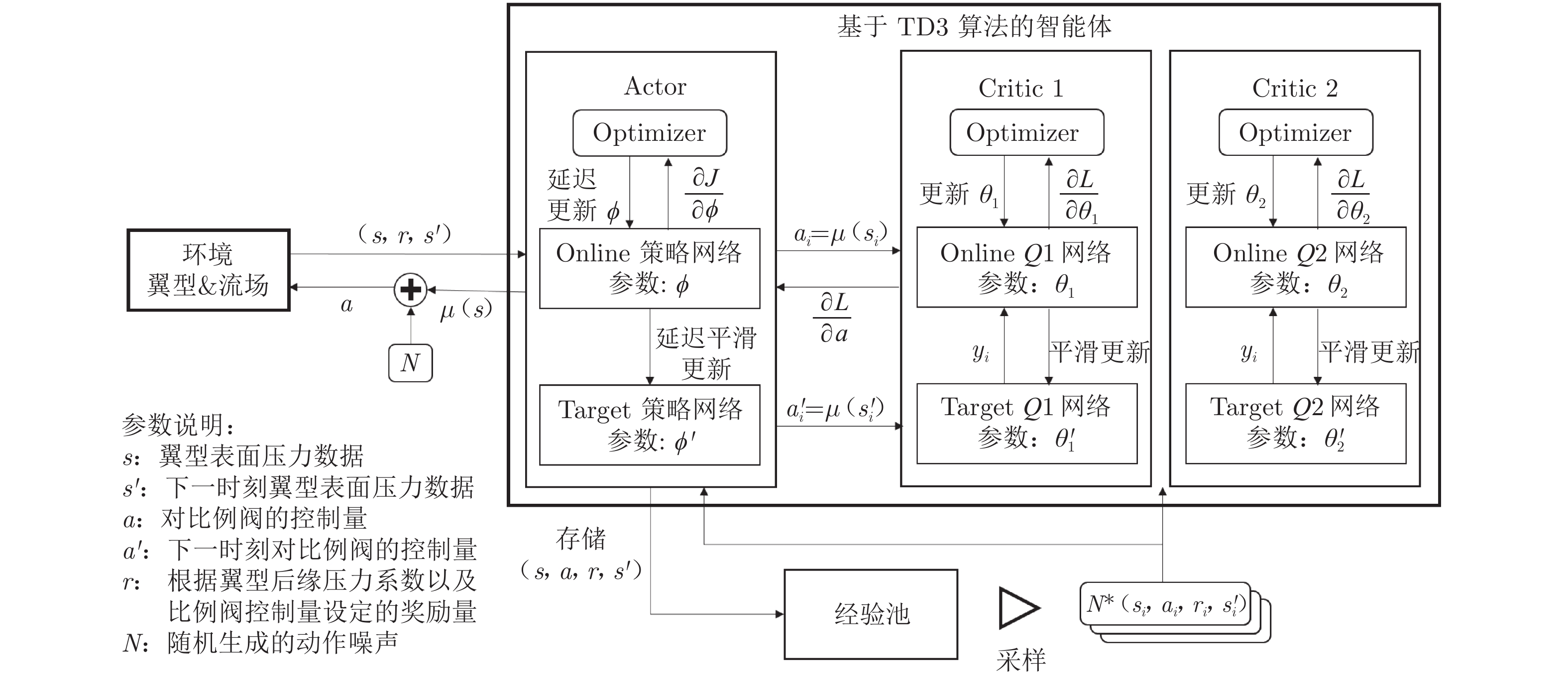
摘要: 搭建了基于深度强化学习(DRL)的射流闭环控制系统,在NACA0012翼型上开展了大迎角分离流动控制实验研究。NACA0012翼型弦长200 mm,实验风速10 m/s,雷诺数1.36×105。射流激励器布置在翼型上表面,通过电磁阀进行无级控制。将翼型表面的压力系数和智能体自身的动作输出作为智能体的观测量,以翼型后缘压力系数为奖励函数,对智能体进行训练。结果表明:经过训练的智能体成功地抑制了大迎角下的流动分离,比定常吹气的费效比降低了50%;智能体可以将翼型后缘压力系数稳定地控制在目标值附近;状态输入和奖励函数的改变会对最终的训练效果产生不同影响。Abstract: A jet closed-loop control system based on Deep Reinforcement Learning (DRL) was built, and an experimental study was carried out on the separation flow control at high angles of attack on the NACA0012 airfoil. The airfoil chord length is 200 mm and the wind speed was 10 m/s. The Reynolds number was 1.36×105 based on the chord length. The jet actuator was arranged on the upper surface of the airfoil and the solenoid valve was used for stepless control. The pressure coefficient of the airfoil surface and the action output of the agent itself were taken as the observation of the agent. The pressure coefficient of the trailing edge of the airfoil was used as the reward function to train the agent. Our results showed that the trained agent successfully suppresses the flow separation at high angles of attack and the cost-effectiveness ratio is reduced by 50% compared with steady blowing. At the same time, the agent could also stabilize the pressure coefficient of the trailing edge near the target value. The state input and the change of the reward function also have different effects on the final training effect.
-
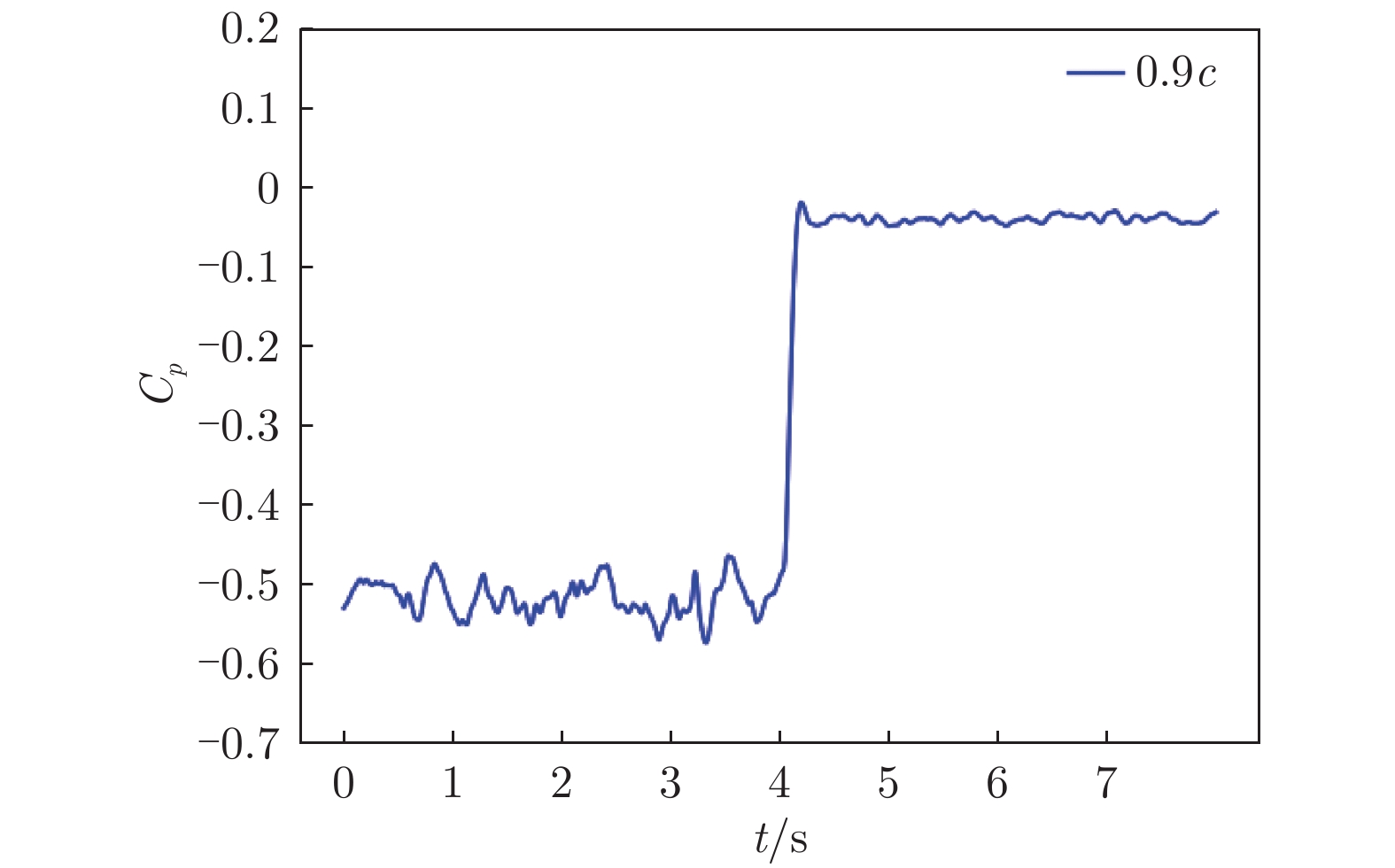
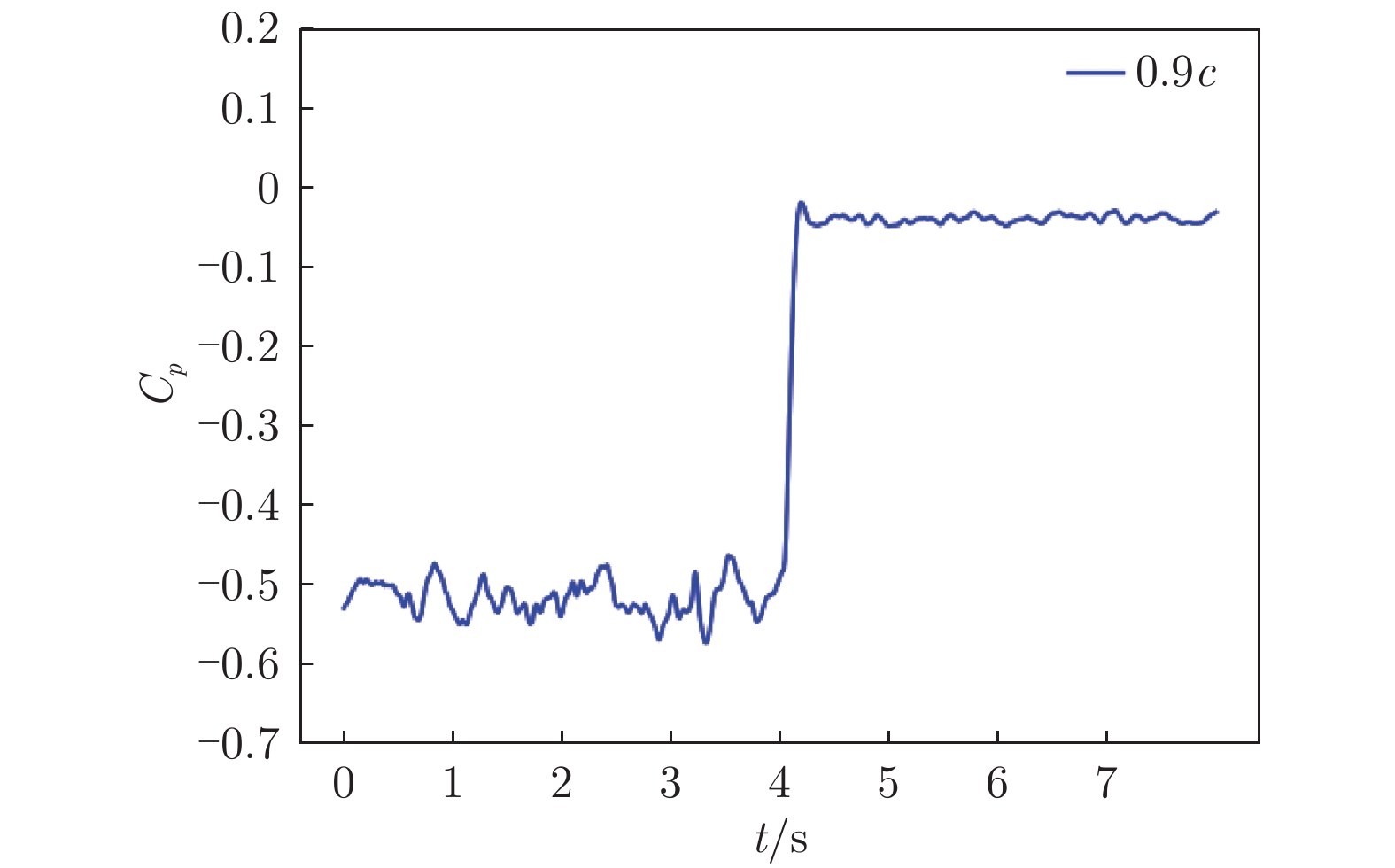
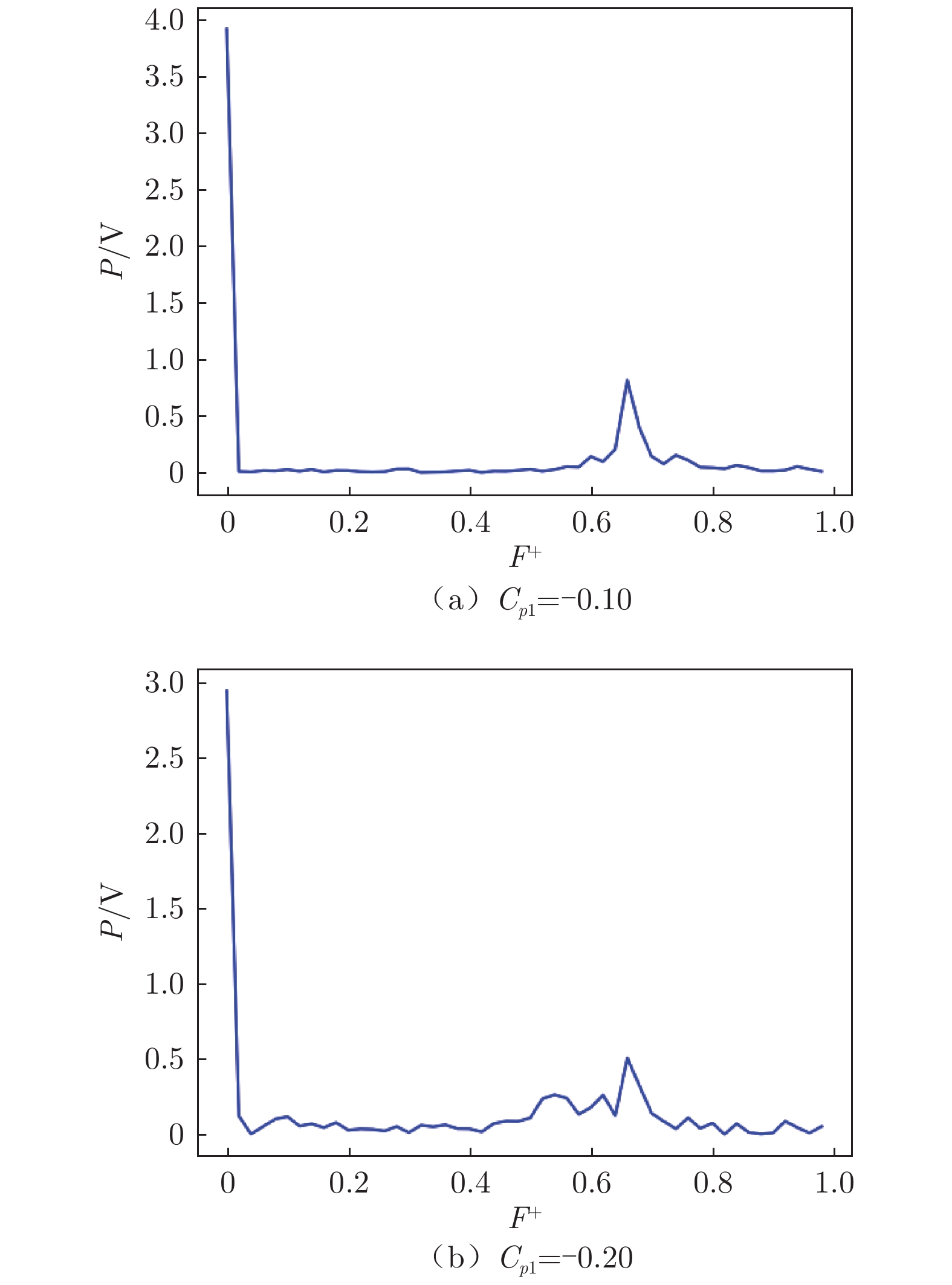
图 6 翼型后缘压力系数随时间变化
Figure 6. Time variation of the pressure coefficient of the airfoil trailing edge
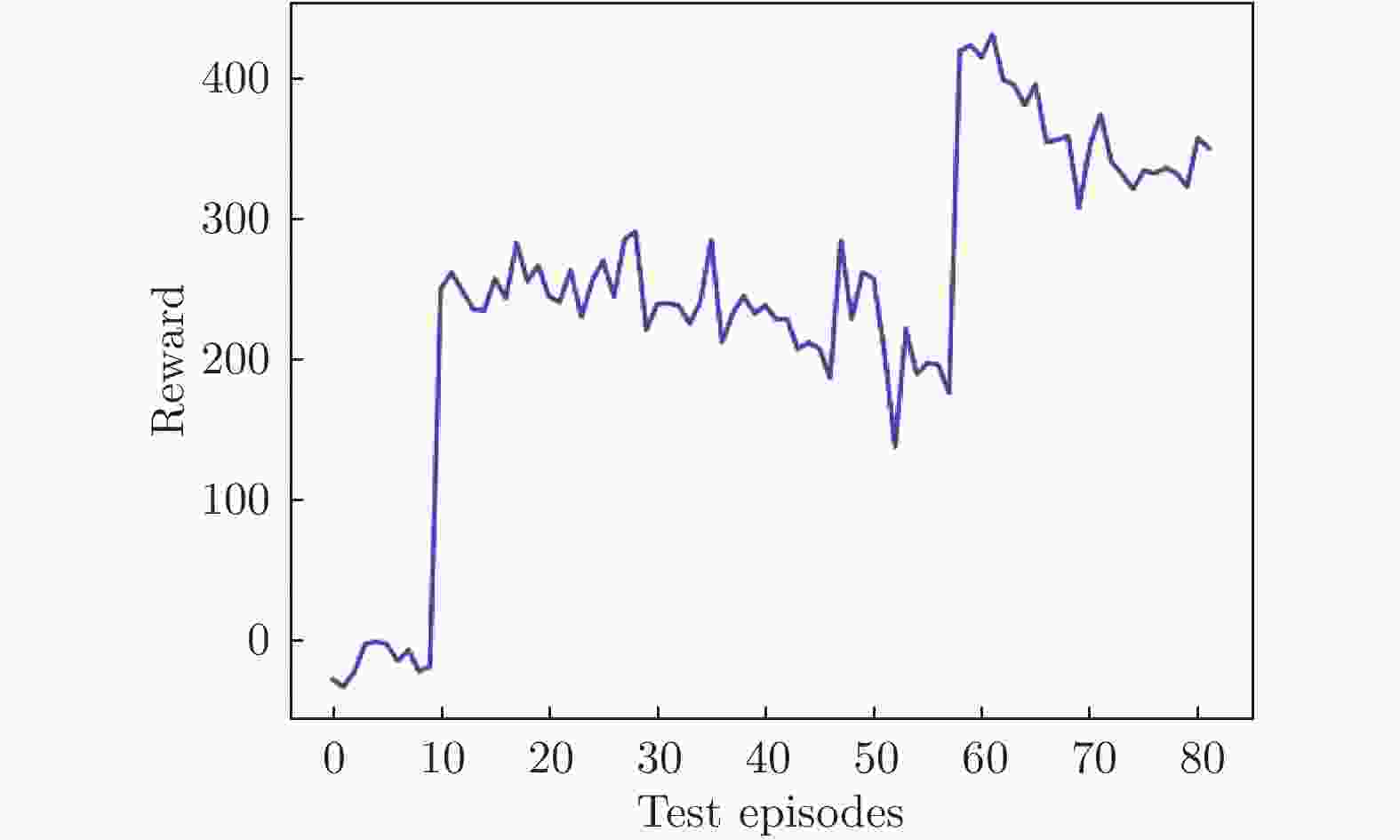
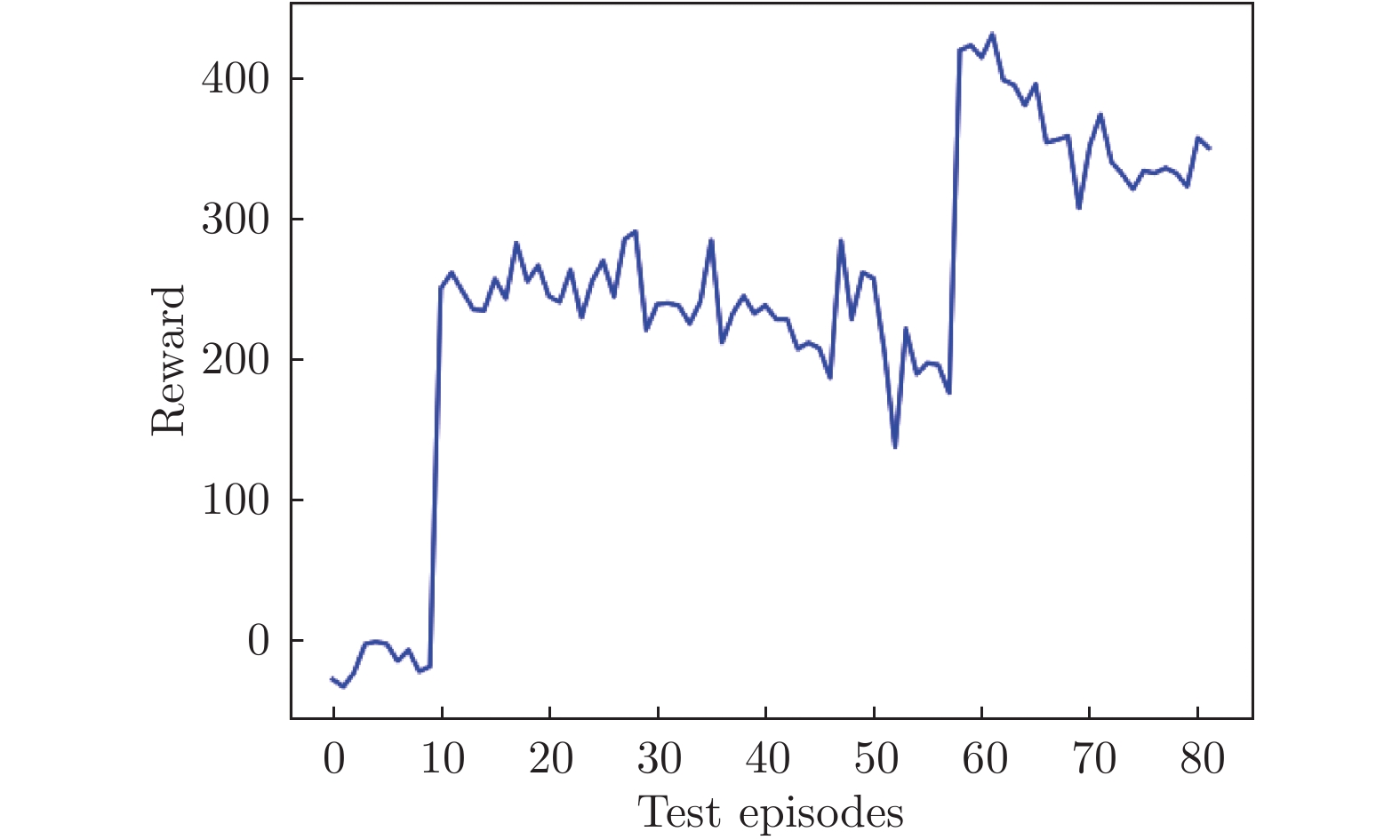
图 8 测试环节总奖励值随幕数变化
Figure 8. The total reward value of the test session varies with episodes
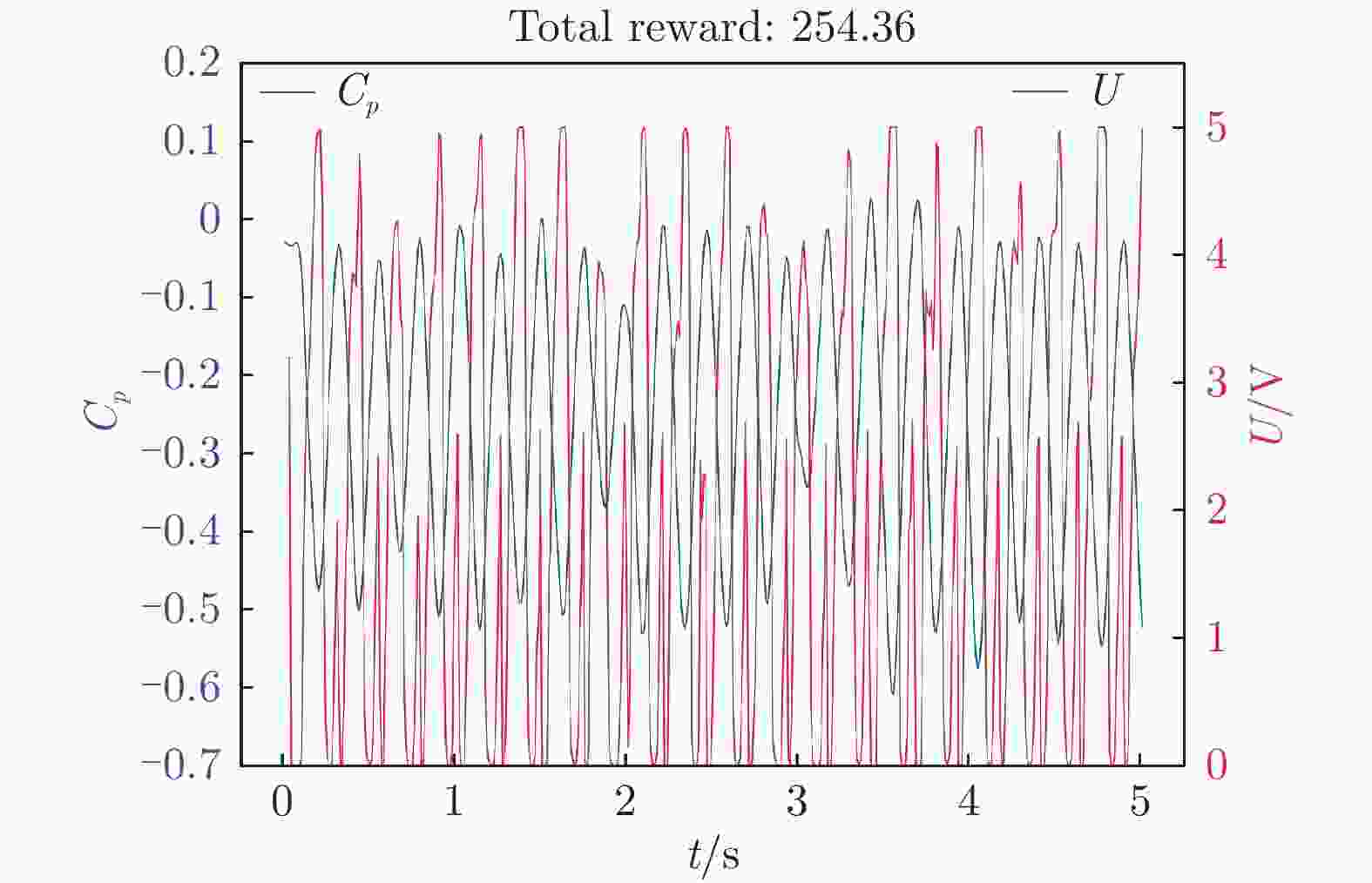
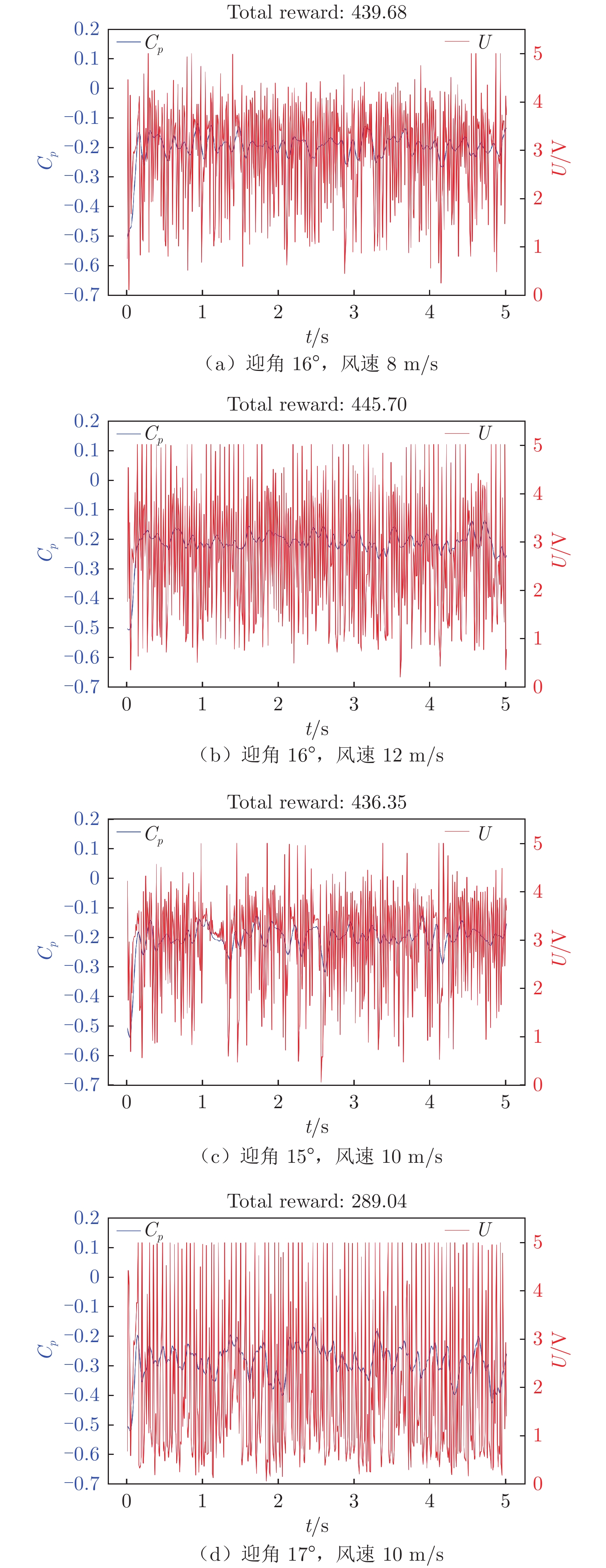
图 9 第20幕测试下翼型后缘压力系数和输出电压随时间变化
Figure 9. Time variation of the pressure coefficient of the airfoil trailing edge and the output voltage at twentieth episode
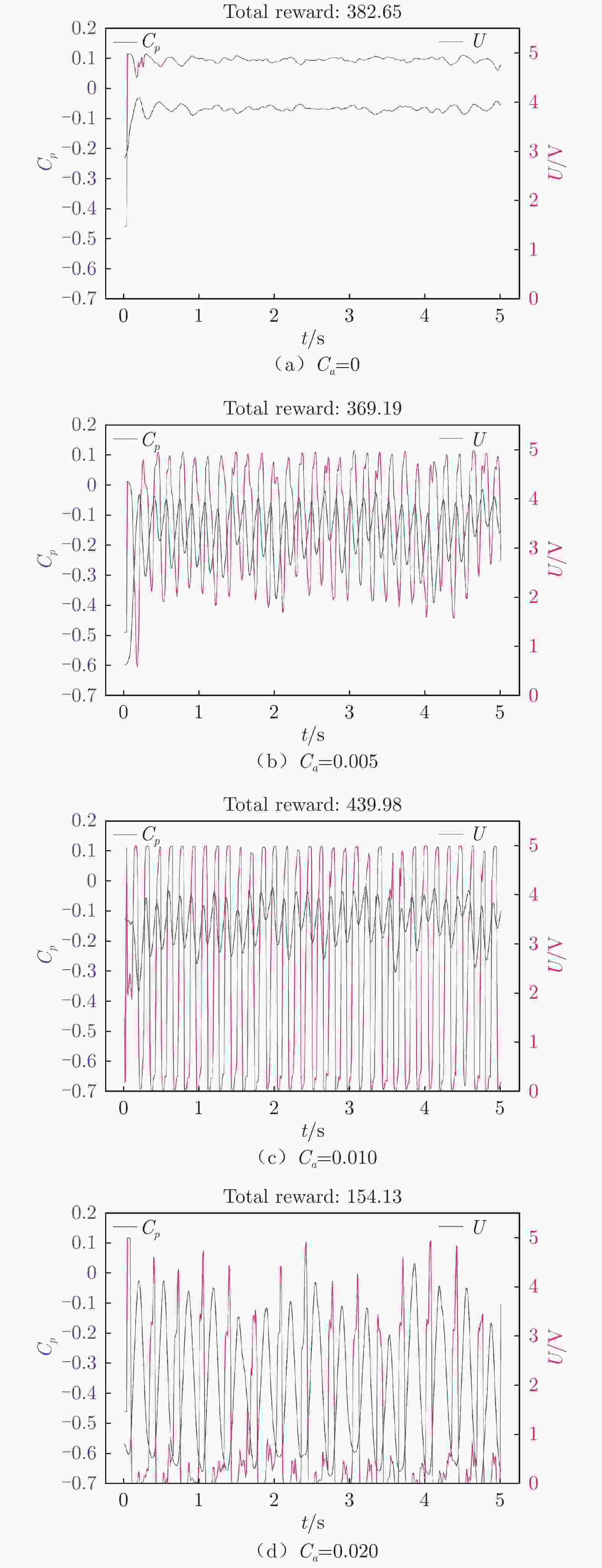
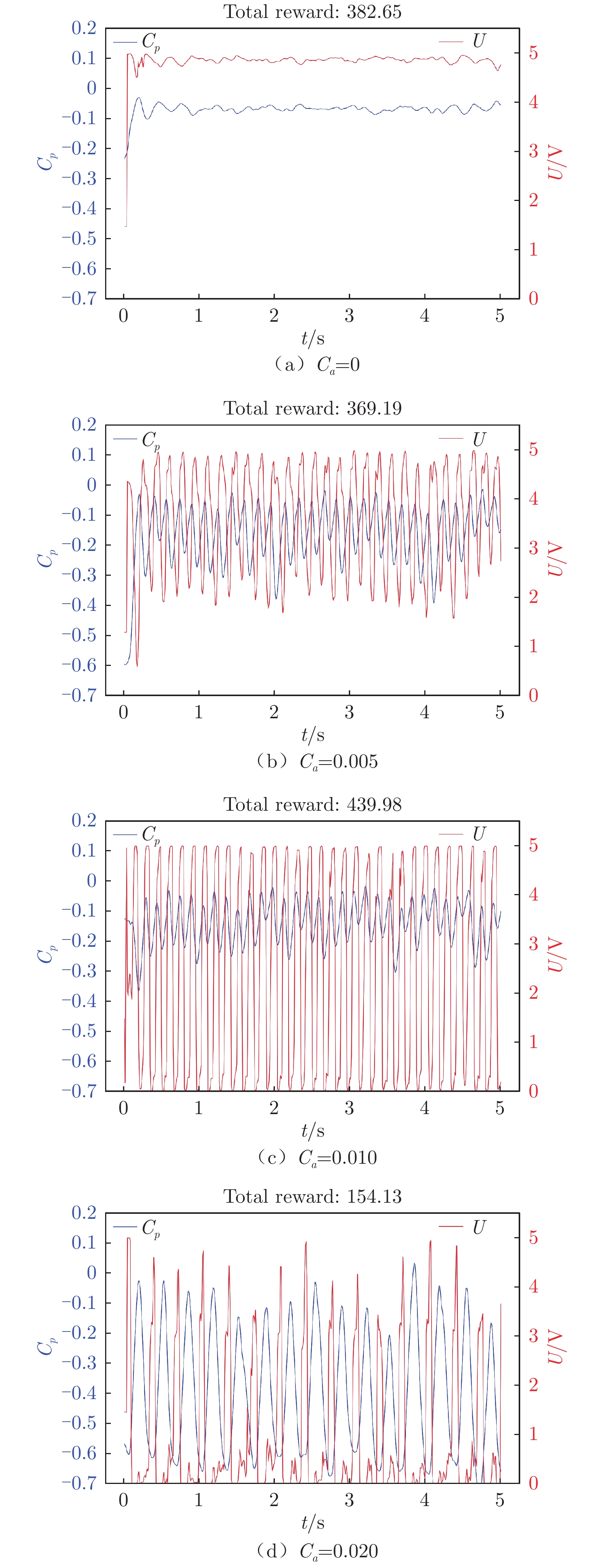
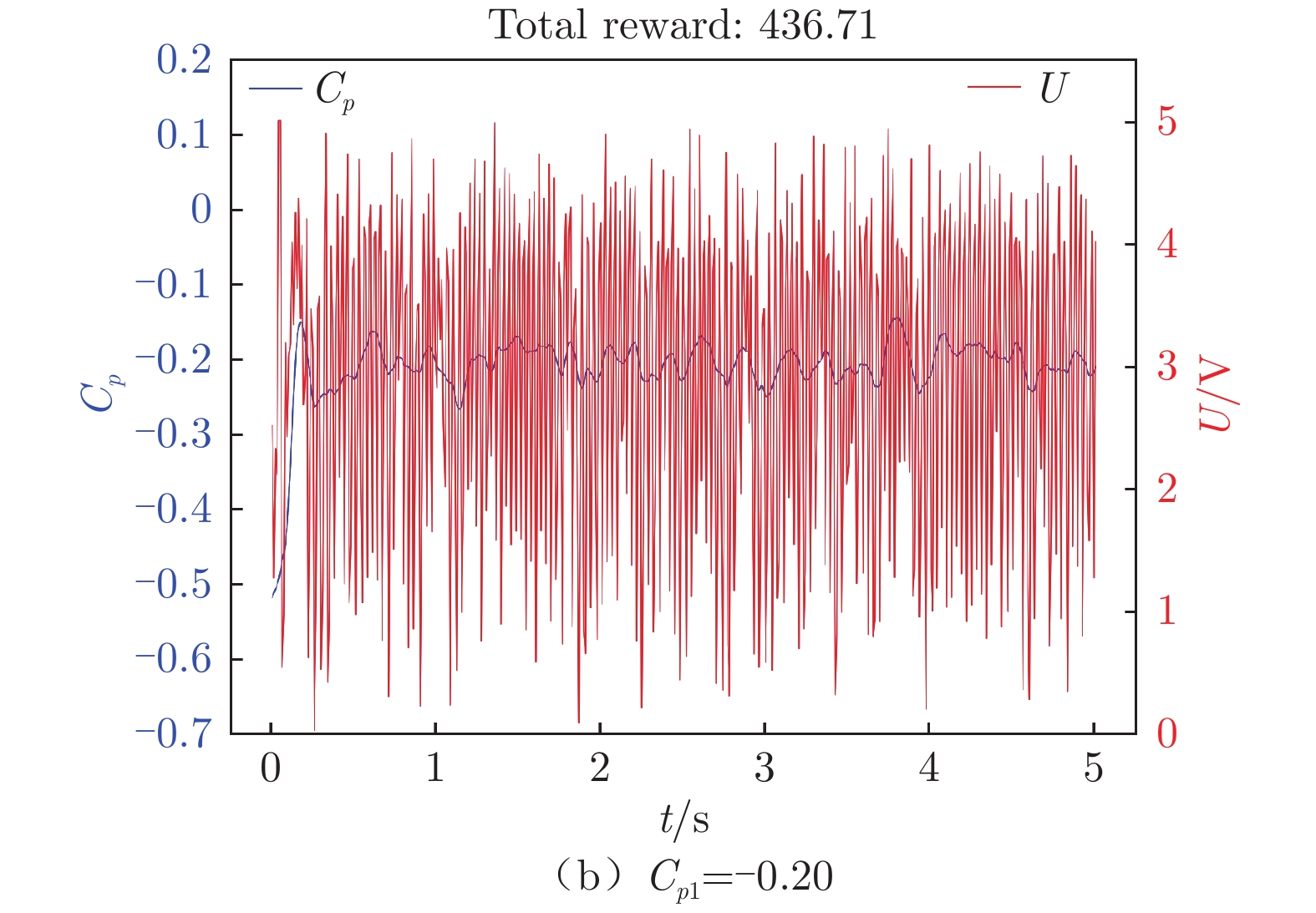
图 10 不同惩罚系数下翼型后缘压力系数和输出电压随时间变化
Figure 10. Time variation of airfoil trailing edge pressure coefficient and output voltage with different Ca
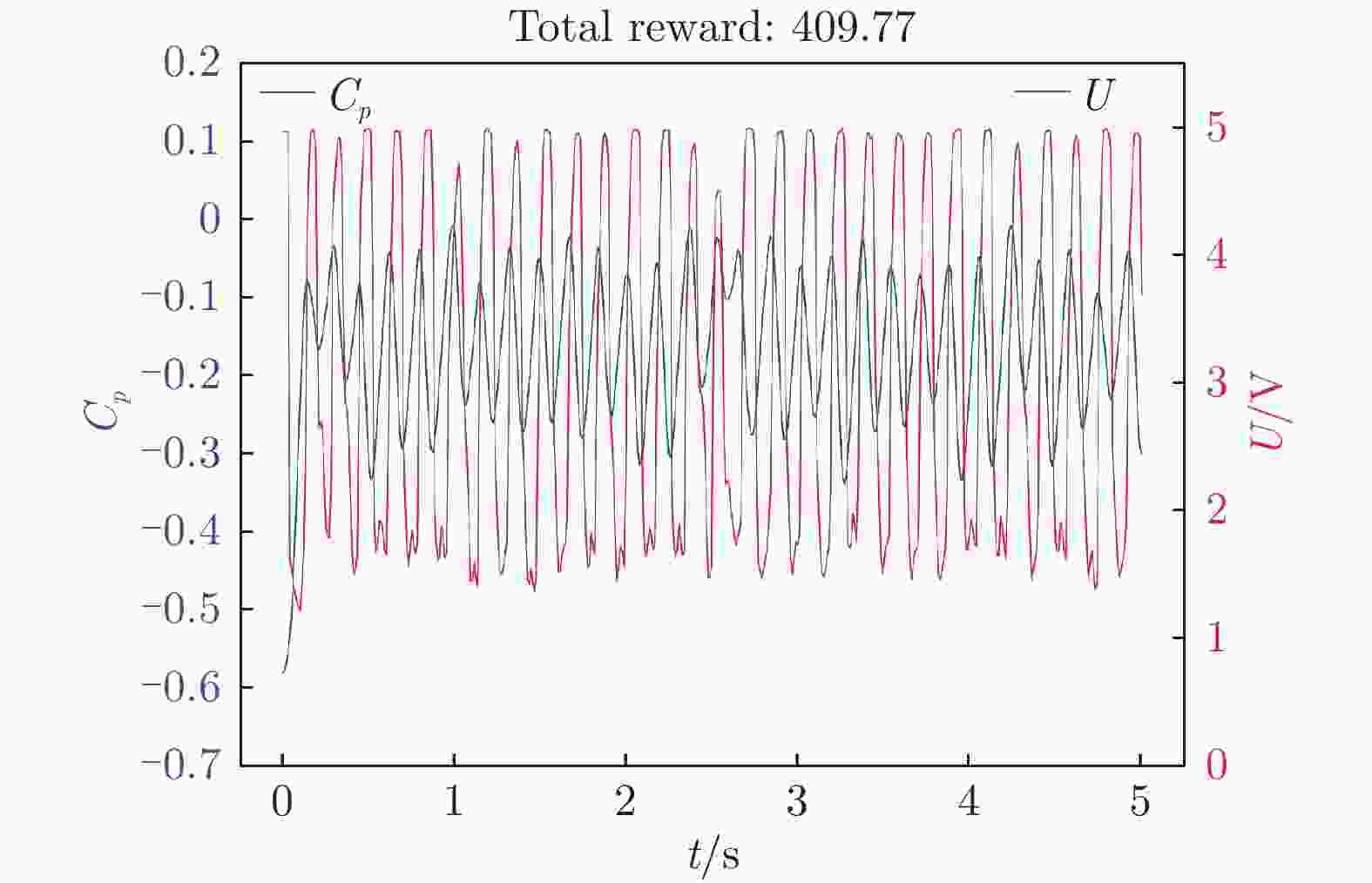
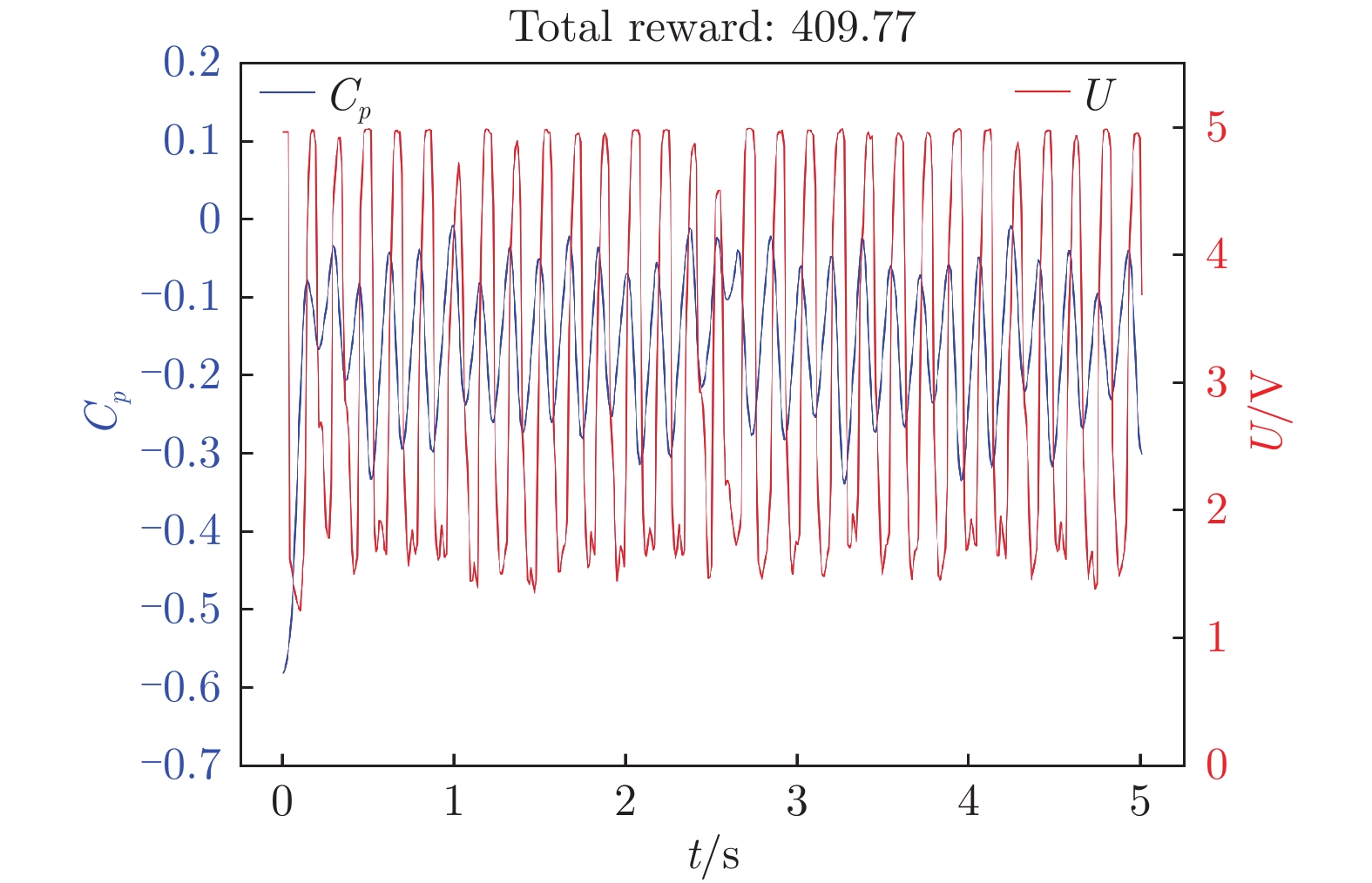
图 11 连续奖励函数下翼型后缘压力系数和输出电压随时间变化
Figure 11. Time variation of continuous reward function airfoil trailing edge pressure coefficient and output voltage

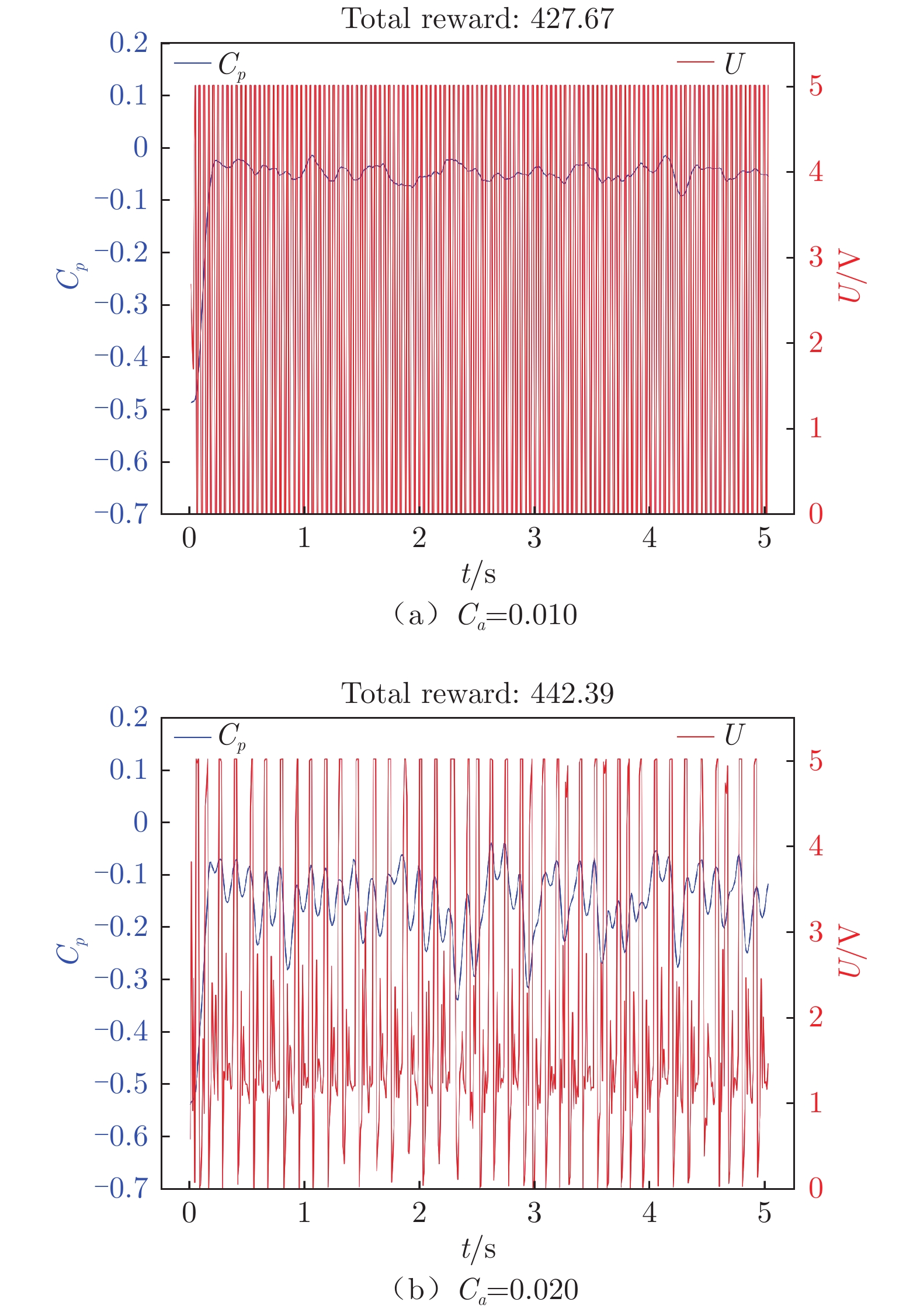
图 12 离散奖励函数、不同惩罚系数下翼型后缘压力系数和输出电压随时间变化
Figure 12. Time variation of airfoil trailing edge pressure coefficient and output voltage with different Ca under discrete rewards
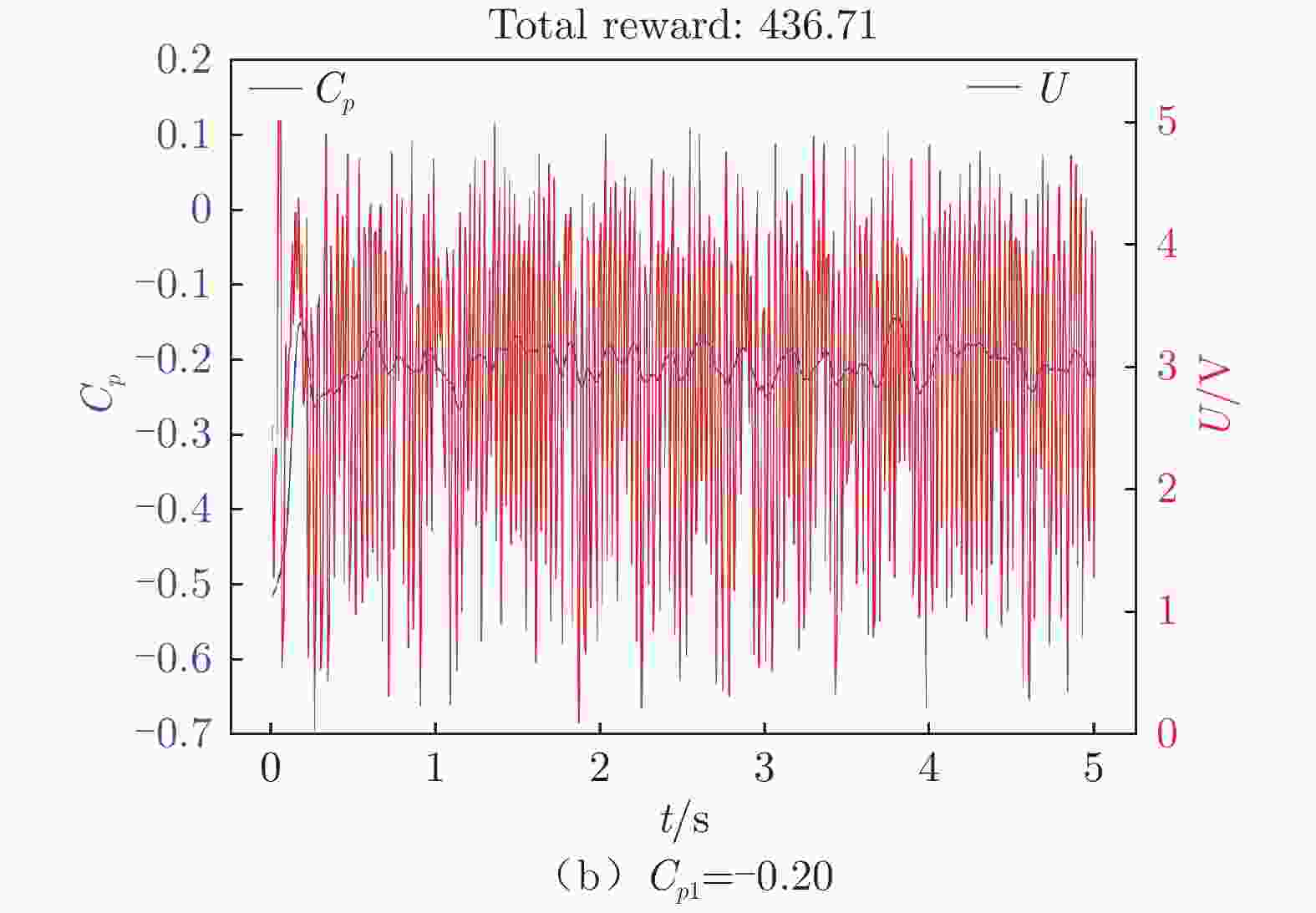
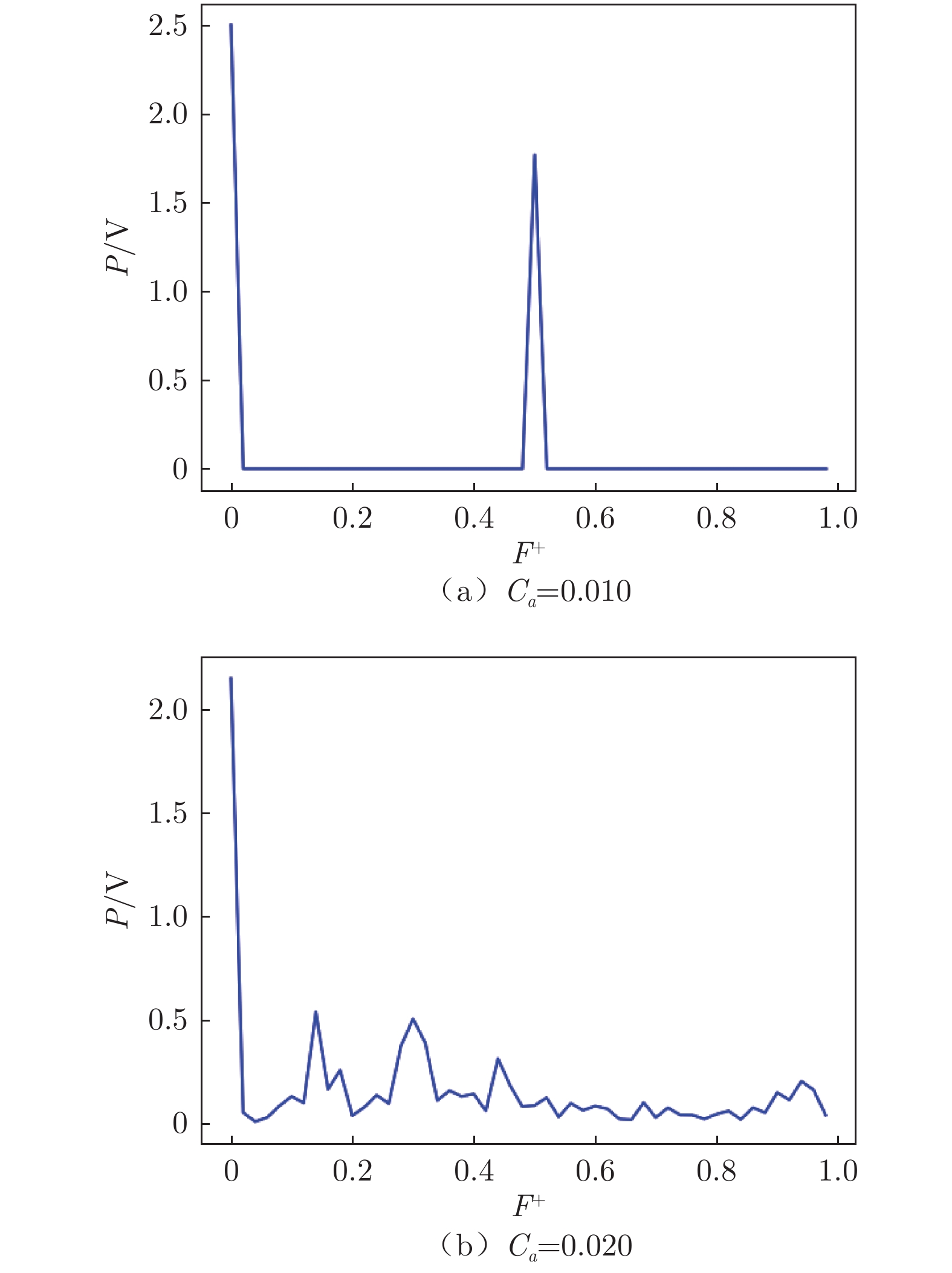
图 14 连续奖励函数下翼型后缘压力系数和输出电压随时间变化
Figure 14. Time variation of continuous reward function airfoil trailing edge pressure coefficient and output voltage
-
[1] SUTTON R S. Learning to predict by the methods of temporal differences[J]. Machine Learning,1988,3(1):9-44. doi: 10.1007/BF00115009 [2] FRANCOIS-LAVET V,HENDERSON P,ISLAM R,et al. An introduction to deep reinforcement learning[J]. Founda-tions and Trends in Machine Learning,2018:219-354. doi: 10.1561/2200000071 [3] GOODFELLOW I, BENGIO Y, COURVILLE A. 深度学习[M]. 赵申剑, 黎彧君, 符天凡, 等译. 北京: 人民邮电出版社, 2017. [4] PINTO L,ANDRYCHOWICZ M,WELINDER P,et al. Asymmetric actor critic for image-based robot learning[J]. Computer Science,2017:1-8. doi: 10.15607/RSS.2018.XIV.008 [5] BAHDANAU D, BRAKEL P, XU K, et al. An actor-critic algorithm for structured prediction[EB/OL]. [2021-08-24]. https://arxiv.org/abs/1607.07086v2. [6] MNIH V,KAVUKCUOGLU K,SILVER D,et al. Playing Atari with deep reinforcement learning[J]. Computer Scien-ce,2013:1-9. [7] SILVER D,SCHRITTWIESER J,SIMONYAN K,et al. Mastering the game of Go without human knowledge[J]. Nature,2017,550(7676):354-359. doi: 10.1038/nature24270 [8] BERNER C, BROCKMAN G, CHAN B, et al. Dota 2 with large scale deep reinforcement learning[EB/OL]. [2021-08-24]. https://arxiv.org/abs/1912.06680v1. [9] THE ALPHASTAR TEAM. AlphaStar: Mastering the real-time strategy game StarCraft II[EB/OL]. [2021-08-24]. https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii. [10] BROWN N,SANDHOLM T. Superhuman AI for multi-player Poker[J]. Science,2019,365(6456):885-890. doi: 10.1126/science.aay2400 [11] KENDALL A, HAWKE J, JANZ D, et al. Learning to drive in a day[C]//Proc of the 2019 International Conference on Robotics and Automation(ICRA). 2019. [12] BEWLEY A, RIGLEY J, LIU Y X, et al. Learning to drive from simulation without real world labels[C]//Proc of the 2019 International Conference on Robotics and Automation(ICRA), 2019. doi: 10.1109/ICRA.2019.8793668 [13] KNIGHT W. Google just gave control over data center cooling to an AI [EB/OL]. [2021-08-24]. https://www.technologyreview.com/s/611902/google-just-gave-control-over-data-center-cooling-to-an-ai. [14] CHNG T L,RACHMAN A,TSAI H M,et al. Flow control of an airfoil via injection and suction[J]. Journal of Aircraft,2009,46(1):291-300. doi: 10.2514/1.38394 [15] COIRO D P,BELLOBUONO E F,NICOLOSI F,et al. Improving aircraft endurance through turbulent separation control by pulsed blowing[J]. Journal of Aircraft,2008,45(3):990-1001. doi: 10.2514/1.33268 [16] VERMA S,NOVATI G,KOUMOUTSAKOS P. Efficient collective swimming by harnessing vortices through deep reinforcement learning[J]. Proceedings of the National Academy of Sciences of the United States of America,2018,115(23):5849-5854. doi: 10.1073/pnas.1800923115 [17] SHIMOMURA S, SEKIMOTO S, FUKUMOTO H, et al. Preliminary experimental study on closed-loop flow separa-tion control utilizing deep Q-network over fixed angle-of-attack airfoil[C]//Proc of the 2018 Flow Control Conference. 2018. doi: 10.2514/6.2018-3522 [18] GUÉNIAT F,MATHELIN L,HUSSAINI M Y. A statistical learning strategy for closed-loop control of fluid flows[J]. Theoretical and Computational Fluid Dynamics,2016,30(6):497-510. doi: 10.1007/s00162-016-0392-y [19] PIVOT C, CORDIER L, MATHELIN L. A continuous reinforcement learning strategy for closed-loop control in fluid dynamics[C]//Proc of the 35th AIAA Applied Aero-dynamics Conference. 2017. doi: 10.2514/6.2017-3566 [20] XU H,ZHANG W,DENG J,et al. Active flow control with rotating cylinders by an artificial neural network trained by deep reinforcement learning[J]. Journal of Hydrodynamics,2020,32(2):254-258. doi: 10.1007/s42241-020-0027-z [21] RABAULT J,KUCHTA M,JENSEN A,et al. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control[J]. Journal of Fluid Mechanics,2019,865:281-302. doi: 10.1017/jfm.2019.62 [22] TANG H W,RABAULT J,KUHNLE A,et al. Robust active flow control over a range of Reynolds numbers using an artificial neural network trained through deep reinforce-ment learning[J]. Physics of Fluids,2020,32(5):053605. doi: 10.1063/5.0006492 [23] FUJIMOTO S, VAN HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[EB/OL]. [2021-08-24]. https://arxiv.org/abs/1802.09477 2018: arXiv:1802.09477[cs.AI]. -

 下载:
下载:




 点击查看大图
点击查看大图

计量
- 文章访问数: 1691
- HTML全文浏览量: 346
- PDF下载量: 81
- 被引次数: 0